[ArbLab] 2. OU Process (1) Caveats in Calibrating the OU Process
O-U process로 모델링하고 Parameter 추정하다보면 가장 안되는게 \(\theta\)의 추정이다
그에 대한 상세한 설명인 포스트!
KEY TAKEAWAYS
추정량의 편향 및 분산
\(\theta\)의 추정량은 편향되며 AR(1) 기반 방법에서는 큰 분산을 가진다. 원칙적으로 개선하기 매우 어렵다.
\(\theta\)가 과대 추정되는 경우가 많기 때문에 페어 트레이딩 시나리오에서는 모델이 너무 낙관적일 수 있다. 빠른 평균 회귀가 더 많은 수익을 나타내기 때문
직접 최대 가능도 방법
이 방법은 최대 가능도 추정기를 사용하는 경우, 알려진 평균을 가진 AR(1) 방법과 동일한 결과를 산출한다
다소 느리다
신뢰하지 말아야 할 상황
평균 회귀 속도가 작거나, 평균 회귀의 반감기가 큰 경우 (예: 기간 내 평균을 20회 이하로 교차하는 경우).
샘플 크기가 충분하지 않은 경우 (예: 1년 이하의 일별 데이터
\(\sigma\)와 \(\mu\) 추정의 신뢰성
\(\sigma\) (변동성)와 \(\mu\) (평균)의 추정은 일반적으로 \(\theta\) 추정보다 더 신뢰할 수 있다
노이즈와 점프의 영향
노이즈와 점프는 상황을 더욱 복잡하게 만들 수 있으며, 이를 신중하게 처리해야 한다
OU process
O-U 과정은 가장 간단한 연속 시간 평균 회귀 모델(continuous-time mean-reverting model)이다. 그 단순성 덕분에 금융 리스크 관리, 이자율 모델링, 페어 트레이딩 등 다양한 정량 금융 분야에서 널리 사용된다. 대부분의 문제가 해결된 잘 연구된 분야이나, 실무자가 직면하게 되는 일반적인 문제는 최근에야 다루어지기 시작하였다.
OU process의 SDE
\[dX_t = \theta(\mu - X_t)dt + \sigma dW_t,\]
- \(\theta\): 평균 회귀 속도 (mean-reverting speed), positive constant
- \(\mu\): 장기 평균 (long-term average), positive constant
- \(\sigma\): standard deviation for the Brownian part (scaling factor), positive constant
- \(X_t\): 현재 값
- \(W_t\): Standard Wiener/Brownian process
\[\theta (\mu - X_t) dt\]
현재 값 \(X_t\)가 평균 \(\mu\)로 돌아가려는 경향을 나타낸다. \(\theta\)가 클수록 평균 회귀 속도가 빠르다.
평균 회귀 속도 \(\theta\)를 정확하게 추정하는 것은 일반적으로 어렵다.
\[\sigma dW_t\]
Standard Wiener/Brownian 과정에서 오는 무작위적인 변동성을 나타낸다.
Generating OU process
몬테카를로 방법은 확률 과정 분석에 널리 사용되며, O-U 과정의 시뮬레이션에도 유용하다
일반적으로 OU process를 생성하는 두 가지 방법이 있다
Euler Scheme (=Euler-Maruyama discretization)
- 이 방법은 OU process SDE를 통해 간단하고 빠르게 구현할 수 있지만, discretization errors가 생길 수 있다.
- OU process의 analytical solution 을 사용한다
\[ X_t = X_0 e^{-\theta t} + \mu (1 - e^{-\theta t}) + \sigma e^{-\theta t} \int_0^t e^{\theta s} dW_s \]
시간 \( t \)가 일정한 간격으로 나뉜 \(\{X_t\}\), 일반적으로 \( 0 = t_0 < t_1 < \ldots < t_n = T \)와 같은 형태이다.
위 식의 마지막 항인 확률 적분 항만 not deterministic이다.
deterministic part는 미리 계산할 수 있다. 이를 통해 시간을 절약할 수 있으며, deterministic part를 정확하게 계산할 수 있기 때문에 discretization error를 줄일 수 있다.
stochastic past 에 대해서는, 시간 간격 \(\Delta t = t_i - t_{i-1}\)이 충분히 작다면, 이토 적분(It's integral)을 다음과 같이 간단히 근사할 수 있다:
\[ \int_{t_{i-1}}^{t_i} e^{\theta s} dW_s \approx e^{\theta t_{i-1}} \sqrt{t_i - t_{i-1}} W \]- \( W \)는 정규 분포를 따른다: \( W \sim \mathcal{N}(0, 1) \).
- \( \theta \)는 평균 회귀 속도
- \( e^{\theta s} \)는 시간 \( s \)에 대한 지수 함수.
- 이 근사는 \(\Delta t\)가 충분히 작을 때 유효하다.
Doob's exact simulation method
Doob는 \(X_t\)가 다음과 같은 특성을 갖는 normally distributed random variable임을 증명했다.
\[ X_t = e^{-\theta (t-u)} X_u + \mu (1 - e^{-\theta (t-u)}) + \sigma \int_u^t e^{-\theta (t-s)} dW_s \]
- 결정론적 부분(mean): \( \mu_w(u, t) = e^{-\theta (t-u)} X_u + \mu (1 - e^{-\theta (t-u)}) \)
- 확률적 부분(variance): \( \sigma^2_w(u, t) = \sigma^2 \int_u^t e^{-2\theta (t-s)} ds = \frac{\sigma^2}{2\theta} (1 - e^{-2\theta (t-u)}) \)
따라서, \(X_u\)를 알고 있다면 \(X_t\)를 다음과 같이 정확하게 시뮬레이션할 수 있다. 여기서 \(W\)는 표준 정규 분포를 따르는 랜덤 변수이다.
\[ X_t = e^{-\theta (t-u)} X_u + \mu (1 - e^{-\theta (t-u)}) + \sigma_w(u, t) W \\ W \sim \mathcal{N}(0, 1) \]
이 방법은 간단한 Euler-Maruyama 이산화만큼 빠르게 계산할 수 있다. 단지 브라운 운동의 증분을 다음과 같이 변경하여 계산하면 된다.
\[ \sigma \sqrt{\Delta t} W \rightarrow \sigma \sqrt{\frac{1 - e^{-2\theta \Delta t}}{2\theta}} W \]
discretization error는 \( \frac{1 - e^{-2\theta \Delta t}}{2\theta} \)를 \( \Delta t \)로 근사함으로써 발생하는데, 시뮬레이션 정확도에 큰 영향을 미치므로, 실무자들은 정확한 방법을 고려해야 한다.
Estimating Parameters
O-U 과정에서 중요한 세 가지 constants는 평균 회귀 속도(\(\theta\)), 장기 평균(\(\mu\)), 표준 편차(\(\sigma\))이다. 일반적으로 \(\mu\)와 \(\sigma\)는 관측치가 충분히 많다면(250개 이상) 비교적 정확하게 추정할 수 있다.
그러나 \(\theta\)를 정확하게 추정하는 것은 매우 어렵다. 이는 관측치가 많아도 ( 10,000개 : 주식의 1분 간격 데이터로 한 달 이상의 데이터) 어려움을 겪는다. 하지만 사실상 전략의 수익성에 평균 회귀 속도는 큰 관련이 있다
무한개의 샘플이 있는 경우, 아래 방법들은 모두 동일한 결과를 줄 것이다. 하지만 유한 샘플의 경우, 특히 \(\theta\)가 작을 때, 매우 다른 편향 프로파일을 나타낼 수 있다
우리는 \(\theta\) 값이 커서 더 많은 회귀현상이 있는것을 원하고 게다가 많은 분석이 평균 회귀의 half-life를 기반으로 하는데 O-U 과정에서 half-life는 \(\theta\)를 사용하여 다음과 같이 계산된다
\[ H = \frac{\ln(2)}{\theta} \]
Parameter Estimation - AR(1) approach
AR(1) process O-U 과정을 이산화하여 선형 회귀를 수행하고 매개변수를 추정하여 AR(1) 과정의 매개변수를 O-U 과정의 매개변수로 변환한다.
가장 일반적인 접근법은 OU process 의 discrete data를 AR(1) process로 간주하고 두 매개변수를 추정하는 것이다. 일정한 시간 간격 \(\Delta t\)를 갖는 AR(1) 과정은 다음과 같다:
\[ X_i = \alpha + \phi X_{i-1} + \sigma_\epsilon W_i \]
따라서, 선형 회귀를 수행하여 \(\alpha\), \(\hat{\phi}\), \(\sigma_\epsilon\)를 찾을 수 있다. 위의 방정식을 O-U 과정의 매개변수와 비교하기 위해 다음과 같이 재작성할 수 있다:
\[ X_i - X_{i-1} = \alpha + (\phi - 1)X_{i-1} + \sigma_\epsilon W_i \]
이 경우, O-U 과정의 매개변수는 다음과 같이 추정할 수 있다:
\[ \hat{\theta} = \frac{1 - \hat{\phi}}{\Delta t}, \quad \hat{\sigma} = \sqrt{\frac{\sigma_\epsilon^2}{\Delta t}}, \quad \hat{\mu} = \frac{\hat{\alpha}}{1 - \hat{\phi}} \]
여기서 \(\sigma_\epsilon^2\)는 OLS(최소자승법)의 잔차(residuals)의 평균 제곱 오차이다. OLS를 사용하고 있으므로, 계수 \(\hat{\phi}\)에 대한 analytical solution을 직접 구할 수 있다
\[ \hat{\phi} = \frac{\sum_{i=1}^N (X_i - \hat{\alpha})(X_{i-1} - \hat{\alpha})}{\sum_{i=1}^N (X_{i-1} - \hat{\alpha})^2} \]
Tang과 Chen(2009)에 따르면, 최대 가능도 추정법을 사용하면 약간 더 나은 결과를 얻을 수 있다고 한다
\[ \hat{\theta} = -\frac{\ln(\hat{\phi})}{\Delta t} \]
대부분의 경우, 원본 데이터와 그 시차 1 값이 매우 유사하기 때문에 최대 가능도 추정법을 사용한 결과는 직접적인 AR(1) 접근법과 크게 다르지 않다. \(\hat{\phi} \approx 1\)이므로 \(\ln(\hat{\phi}) \approx \hat{\phi} - 1\)이다.
Parameter Estimation - AR(1) approach with Known Mean
알려진 평균을 사용하는 경우 AR(1)의 결과를 개선할 수 있다.
추정량이 실제 응용에서 양의 편향을 가지며, 이는 평균 회귀 빈도를 과대 평가하는 경향이 있다.
프로세스의 장기 평균이 알려져 있을 때, AR(1) 접근법의 결과는 다음과 같이 향상 될 수 있다:
\[ \hat{\phi} = \frac{\sum_{i=1}^N X_i X_{i-1}}{\sum_{i=1}^N X_{i-1}^2}, \quad \hat{\theta} = -\frac{\ln(\hat{\phi})}{\Delta t} \]
다른 두 변수(\(\hat{\theta}\)와 \(\sigma\))는 이전과 동일하게 유지된다. 가격 pair로 부터 mean-reverting spread를 모델링할때 일반적으로 장기 평균은 0으로 간주한다. 따라서 이 가정은 현실적이라 볼 수 있다.
\(\hat{\theta}\)의 정확한 분포는 Bao et al. (2015)에 의해 다양한 현실적 조건(알려진 또는 알려지지 않은 \(\mu\), 고정 또는 랜덤 초기 값 등)에서 연구되었다. 실제 응용에서 샘플이 유한한 경우, 이 추정량은 항상 양의 편향을 가지고 있다. 따라서 페어 트레이딩에 적용될 때, 이 방법은 일반적으로 주어진 기간 동안 평균 회귀 빈도를 과대 평가하는 경향이 있다.
Parameter Estimation - Direct Max-Likelihood [Implemented]
MLE는 OLS보다 약간 더 나은 결과를 제공한다
이 방법도 \(\mu=0\) 이다. 다만 나머지 두개의 parameter \((\theta, \sigma)\)의 MLE 직접 사용하는 방법을 활용한다. 이 방법은 조건부 데이터에서 MLE를 직접 계산한다.
\[ X_t = e^{-\theta \Delta t} X_{t-1} + \sigma \sqrt{\frac{1 - e^{-2\theta \Delta t}}{2\theta}} W \]
Doob의 결과를 사용하여, \(X_t\)는 평균이 \(e^{-\theta \Delta t} X_{t-1}\)이고 표준 편차가 \(\sigma \sqrt{\frac{1 - e^{-2\theta \Delta t}}{2\theta}}\)인 정규 분포를 따른다.
즉, \(X_{t-1}\)이 주어졌을 때의 conditional density 는 다음과 같이 정규 분포를 따른다
\[ f(X_t|X_{t-1}; \theta, \sigma) = \frac{1}{\sigma_w \sqrt{2\pi}} \exp \left( -\frac{(X_t - X_{t-1} e^{-\theta \Delta t})^2}{2\sigma_w^2} \right) \]
여기서 \(\sigma_w = \sigma \sqrt{\frac{1 - e^{-2\theta \Delta t}}{2\theta}}\)이다
이제 데이터가 주어졌을 때 log-likelihood의 합은 다음과 같다
\[ \mathcal{L}(\theta, \sigma | X_1, \ldots, X_N) = -\frac{N \ln(2\pi)}{2} - N \ln(\sigma_w) - \frac{1}{2\sigma_w^2} \sum_{i=1}^N (X_i - X_{i-1} e^{-\theta \Delta t})^2 \]
@staticmethod
def _compute_log_likelihood(params, *args):
"""
평균 로그 우도를 계산합니다. (p.13)
:param params: (tuple) A tuple of three elements representing mu, theta and sigma_squared.
mu, theta, sigma_squared를 나타내는 세 요소의 튜플.
:param args: (tuple) All other values that to be passed to self._compute_log_likelihood()
self._compute_log_likelihood()에 전달될 다른 모든 값들.
:return: (float) The average log likelihood from given parameters.
주어진 매개변수로부터 계산된 평균 로그 우도.
"""
# Setting given parameters
# 주어진 매개변수 설정
mu, theta, sigma_squared = params
X, dt = args
n = len(X)
# Calculating log likelihood
# 로그 우도 계산
sigma_tilde_squared = sigma_squared * (1 - np.exp(-2 * theta * dt)) / (2 * theta)
summation_term = sum((X[1:] - X[:-1] * np.exp(-theta * dt) - mu * (1 - np.exp(-theta * dt))) ** 2)
summation_term = -summation_term / (2 * n * sigma_tilde_squared)
log_likelihood = (-np.log(2 * np.pi) / 2) \
+ (-np.log(np.sqrt(sigma_tilde_squared))) \
+ summation_term
return -log_likelihood\(\mathcal{L}\)을 최대화하기 위해 gradient descent나 L-BFGS-B를 사용할 수 있다. 이 방법은 위에서 논의된 AR(1) 기반 방법들보다 느리지만, pure OU process ( 평균 \(\mu\)가 일정하고, 변동성 \(\sigma\)가 고정된 형태)에서는 AR(1) estimator with known mean.동일한 결과를 생성한다
Parameter Estimation - Moment Estimation Approach
continuous OU process의 Doob’s exact discretization부터 시작해보자
\[ X_t = e^{-\theta(t)} X_0 + \mu (1 - e^{-\theta(t)}) + \sigma \int_0^t e^{-\theta(t-s)} dW_s \]
Doob의 결과와 \( X_0 \sim \mathcal{N}(\mu, \sigma^2/2\theta) \) 가정을 사용하면 \( X_t \)는 다음 모멘트를 가지는 정규 분포를 따른다
\begin{align*} \mathbb{E}[X_t] &= \mu \\ \text{Var}[X_t] &= \frac{\sigma^2}{2\theta} \\ \text{Covar}[X_t, X_s] &= \frac{\sigma^2}{2\theta} e^{-\theta|t-s|}, \quad t \neq s. \end{align*}
\(\mu = 0\)이라고 가정하면, 추정량을 다음과 같이 계산할 수 있다
\[ \hat{\phi} = \frac{\text{Covar}[X_t, X_{t-1}]}{\text{Var}[X_t]}, \quad \hat{\theta} = -\frac{\ln(\hat{\phi})}{\Delta t} \]
편향되지 않은 분산 및 공분산 추정량을 사용하여 어찌저찌 잘해보면
\[ \hat{\phi} = \frac{\sum_{i=1}^N X_i X_{i-1}}{\sum_{i=1}^N X_{i-1}^2} - \frac{N}{N-1}, \quad \hat{\theta} = -\frac{\ln(\hat{\phi})}{\Delta t} \]
최대 가능도 추정량은 항상 양의 편향을 가지는데, 이 조정은 편향을 줄이는 데 도움이 된다. \( \ln(\frac{N}{N-1})/\Delta t \) 항을 효과적으로 빼줌으로써 편향이 덜 두드러지게 된다. 또한, \(\Delta t\)와 \(\ln(\frac{N}{N-1})\)는 일반적으로 같은 크기이므로 이 항은 무시할 수 없게 한
Asymptotic Distributions of Theta Estimator
AR(1) 방법에서 알려진 평균을 사용한 \(\hat{\theta}\) 추정량은 수학 통계학에서 가장 철저히 연구된 방법 중 하나이다. 이는 direct max-likelihood estimatord와도 일치한다. 하지만 \(\hat{\theta}\)는 편향과 분산의 관점에서 매우 부정확할 수 있기 때문에, 불확실성을 정량화하기 위해 \(\hat{\theta}\)의 전체 분포를 살펴보는 것이 유용할 수 있다.
시나리오별 점근 분포 : \( \theta > 0 \)이라고 가정하고, 일정한 increment \(\Delta t\)로 [0, T] 구간의 discrete data를 가지고 있다고 가정하자.
- \(\mu = 0\)인 경우
- \(T \to \infty, \Delta t \text{ 고정}\):
\[
\sqrt{T}(\hat{\theta} - \theta) \overset{d}{\to} \mathcal{N}\left(0, \frac{2\theta \Delta t}{1 - e^{-2\theta \Delta t}}\right)
\] - . \(T \to \infty, \Delta t \to 0\):
\[
\sqrt{T}(\hat{\theta} - \theta) \overset{d}{\to} \mathcal{N}(0, 2\theta)
\]
- \(T \to \infty, \Delta t \text{ 고정}\):
- \(\mu\)가 알려지지 않은 경우
- \(T \to \infty, \Delta t \text{ 고정}\):
\[
\sqrt{T}(\hat{\theta} - \theta) \overset{d}{\to} \mathcal{N}\left(0, \frac{2\theta \Delta t}{1 - e^{-2\theta \Delta t}}\right)
\] - \(T \to \infty, \Delta t \to 0\):
\[
\sqrt{T}(\hat{\theta} - \theta) \overset{d}{\to} \mathcal{N}(0, 2\theta)
\]
- \(T \to \infty, \Delta t \text{ 고정}\):
즉 \(\mu\)가 0인지 아닌지에 상관없이, \(T \to \infty\)일 때 우리는 편향 없는 추정을 얻는다. 그러나 표준 편차는 \(\sqrt{T}\)에 따라 줄어들기 때문에 수렴 속도는 비교적 느리다.
\(T\)가 고정되어 있을 때, \(\Delta t \to 0\)이면 여전히 추정량에 편향이 존재한다. 이는, 예를 들어, 데이터가 두 날의 데이터만 있고 스프레드의 평균 회귀의 half-life가 한 달인 경우, 주어진 기간 내에서 얻을 수 있는 정보가 매우 제한적이기 때문이다
Estimating the Bias of Theta Estimate
Bao et al. (2015)에서 제시된 analytical solution 을 구성하는 것은 매우 복잡하다. 이는 joint characteristic functions에 대한 이해와 복잡한 함수의 numerical integration을 요구하기 때문이다. Yu (2009)는 이 편향을 근사하는 간단한 방법을 연구했다.
\[ \mathbb{E}[\hat{\theta}] - \theta = \frac{1}{T/\Delta t} \left( 3 + e^{2\theta \Delta t} - \frac{2(1 - e^{-2\theta T})}{T(1 - e^{-2\theta \Delta t})} \right) \]
여기서 \(N = T/\Delta t\)이다. 안타깝게도 이 결과를 낮은 \(\theta\) 값에서 완전히 재현하는 것은 어렵다. 기본 가정에 매우 민감하기 때문이다.
아래 그림은 \(\theta\)에 대한 세가지 방법론의 bias의 차이를 비교해보았다. 각 점은 10000번의 Monte-Carlo Simulation 결과의 평균이다. 3년 동안의 일일 데이터를 \(\sigma = 0.1\), \(\Delta t = 1/252\), \(N = 756\)로 설정하여 생성하였다.

보시다시피 더 많은 정보를 사용할수록 편향이 줄어든다. Regression방법에서는 평균을 모를 때 가장 큰 편향을 갖고 평균이 0임을 알고 있을 때 편향이 크게 줄어든다. 모멘트를 정확하게 계산할 수 있다면 가장 적은 편향을 가진다
아래는 \(\sigma = 0.1\), \(\Delta t = 1/391\), \(N = 3910\)로 설정하여 10일 동안의 1분 간격 데이터를 시뮬레이션해본 결과이다

더 큰 시간 범위를 시뮬레이션하면 전체 편향이 감소한다.
Noises and Jumps
금융 데이터에는 많은 노이즈가 포함되며, 점프도 발생할 수 있다. 이러한 두 가지 현상은 모델 보정에 심각한 영향을 미칠 수 있다.
OU process에 noise가 추가되더라도 원래의 OU 모델 SDE를 여전히 만족한다. 그러나 우리의 관측값은 가우시안 노이즈 \(E_i\)로 오염된 것으로 가정한다.
\[ X_i \leftarrow X_i + E_i, \quad E_i \sim \mathcal{N}(0, \omega^2) \]
이 경우, \(\hat{\theta}\)와 \(\hat{\sigma}\) 추정량은 \(n \to \infty\)일 때 무한한 편향을 가질 수 있다. Holý와 Tomanová (2018)는 추가된 노이즈를 처리할 수 있는 몇 가지 방법을 연구했다.
점프가 있는 경우, 일반적으로 과정을 OU jump process로 모델링한다
\[ dX_t = \theta (\mu - X_t) dt + \sigma dW_t + \ln(J_t) dN_t \]
여기서 \( \ln(J_t) \)는 점프 크기가 정규 분포를 따르고, \(N_t\)는 Poisson arrival process이다. 점프는 \(X_t\) 분포의 극단적인 꼬리에 중요한 영향을 미치며, 결과적으로 OU process 데이터는 더 이상 정규 분포를 따르지 않는다. OU 추정 방법을 맹목적으로 적용하면 \(\hat{\theta}\)와 \(\hat{\sigma}\)는 실제 값보다 항상 더 크게 추정될 것입다. 따라서 점프를 필터링한 후 OU 추정을 적용해야 한다.
Monte-Carlo Results
Experiment 1
이 실험에서는 Euler-Maruyama 이산화 기법과 Doob의 정확한 시뮬레이션 기법을 비교한다. 두 방법 모두 동일한 가우시안 노이즈를 사용하여 직접 비교할 수 있도록 하였다. 사용된 매개변수는 \(\theta = 2\), \(\mu = 0\), \(\sigma = 0.5\), \(\Delta t = 1/252\), \(N = 1000\) discretization error가 시뮬레이션 결과에 어떻게 영향을 미치는지를 보여준다.

파란색 선 (Exact): Doob의 정확한 시뮬레이션 결과
주황색 선 (Simple Euler): Euler-Maruyama 이산화 기법을 사용한 결과
The order 1 discretization error가 누적되기 때문에 각 단계가 이전 단계에 의존함에 따라 눈에 띄는 차이가 발생한다

Expected Distribution (검은 점선) : 예상되는 정규 분포
Exact (파란색 히스토그램) : Doob의 정확한 시뮬레이션 결과의 분포
Simple Euler (주황색 히스토그램) : Euler-Maruyama 이산화 기법을 사용한 결과의 분포
Euler-Maruyama 이산화 방법은 더 넓게 퍼진 분포를 보여주며, 이는 이산화 오류가 누적되었음을 나타낸다.
Exact 시뮬레이션 방법이 예상되는 정규 분포에 더 가까운 결과를 제공한다
아래 실험들에서는 O-U process를 정확히시뮬레이션하고, AR(1) with a known mean으로부터의 추정량의 분포를 분석할 것이다.
Experiment 2
먼저, direct ML estimation을 사용하고 이를 AR(1) 방법과 비교해보자. 이 방법은 상대적으로 느리기 때문에 10,000번의 몬테카를로 경로만 사용하여 추정하였다 이 실험은 두 추정 방법의 유사성을 강조하며, 직접 최대 가능도 추정법이 AR(1) 방법과 거의 동일한 결과를 낼 수 있음을 보여준다

파란색 히스토그램 (\(\hat{\theta}\), ML) direct ML estimation 을 사용한 결과입니다.
주황색 히스토그램 (\(\hat{\theta}\), AR(1)-ML) AR(1) 방법을 사용한 결과입니다.
검은 점선 (\(\theta = 5\)) : 실제 \(\theta\) 값입니다.
파란색 선 (E[\(\hat{\theta}\)] = 6.026, ML) : 직접 최대 가능도 추정법을 사용한 추정값의 평균
주황색 선 (E[\(\hat{\theta}\)] = 6.020, AR(1)-ML) : AR(1) 방법을 사용한 추정값의 평균.
두 방법 모두 추정값이 실제 값 \(\theta = 5\) 주변에 분포되어 있다.
두 방법 모두 약간의 편향을 가지고 있지만, 평균 추정값은 거의 동일하다 (ML: 6.026, AR(1)-ML: 6.020).
아래 두 실험에서는 \(\theta\) 값이 크고 작은 경우에 대한 세 가지 다른 방법의 추정치 분포를 직접적으로 비교하였다. 더 명확한 시각화를 위해 KDE(Kernel Density Estimation) 플롯 스타일을 변경하였다
Experiment 3 에 사용된 매개변수는 \(\theta = 5\), \(\Delta t = 1/252\), \(N = 756\)
아래는 세 가지 방법이 대부분 일치하는 아주 좋은 경우 중 하나이다
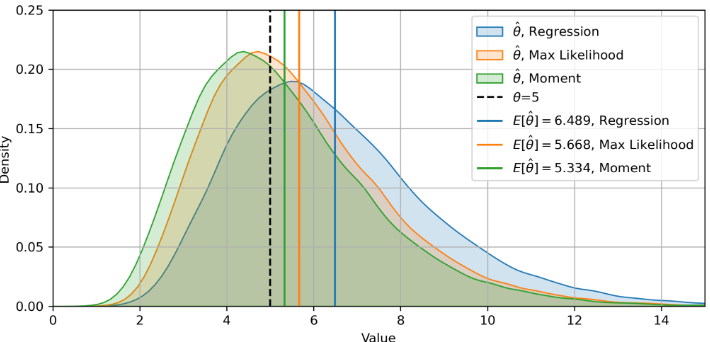
Experiment 4 에 사용된 매개변수는 \(\theta = 0.5\), \(\Delta t = 1/252\), \(N = 504\)
이 경우 상대적 편향이 더 커지며, 일부 추정치가 0보다 작아지는 경우도 있다. 또한, 세 방법 간의 불일치가 크게 확대된다. 이는 \(\theta\)가 작을 때 추정을 신중히 받아들여야 한다는 점을 주지한다.

파란색 곡선 (\(\hat{\theta}\), Regression): 회귀 방법을 사용한 결과.
주황색 곡선 (\(\hat{\theta}\), Max Likelihood): 최대 가능도 추정법을 사용한 결과.
녹색 곡선 (\(\hat{\theta}\), Moment): 모멘트 방법을 사용한 결과.
검은 점선 (\(\theta \)): 실제 \(\theta\) 값.
파란색 선 (E[\(\hat{\theta}\)], Regression): 회귀 방법을 사용한 추정값의 평균.
주황색 선 (E[\(\hat{\theta}\)], Max Likelihood): 최대 가능도 추정법을 사용한 추정값의 평균.
녹색 선 (E[\(\hat{\theta}\)] , Moment): 모멘트 방법을 사용한 추정값의 평균.
Simulation Paths

두 개의 O-U paths 가 평균 회귀 속도가 상대적으로 크기 때문에 빠르게 평균으로 되돌아가는 경향을 보인다.
평균 회귀 속도가 빠르므로 경로가 급격히 변화하지 않고 안정적인 패턴을 보인다
\(\theta\)가 크므로 반감기가 짧아, 경로가 평균값 주변으로 빠르게 수렴한다

두 개의 O-U paths가 평균 회귀 속도가 작기 때문에 평균으로 되돌아가는 속도가 느리다
평균 회귀 속도가 느리므로 경로가 더 넓은 범위에서 변동하며, 평균값으로의 수렴이 더디게 이루어진다
\(\theta\)가 작으므로 반감기가 길어, 경로가 평균값 주변으로 느리게 수렴한다.
https://hudsonthames.org/caveats-in-calibrating-the-ou-process/