Machine Learning for Asset Managers
[ML4AM] 3.Codependence (1) Correlation
알파트로스
2024. 7. 1. 21:41
Pearson Correlation
가장 널리쓰이는 두 random variable 간의 선형적 연관성을 정량화하는 방법이다
\[\rho[X, Y] = \frac{\sigma[X, Y]}{\sigma[X]\sigma[Y]}\]

- Requirements : \(\sigma[X, Y] = \rho[X, Y]\sigma[X]\sigma[Y]\)
이 요구 조건은 두 변수 간의 공분산이 상관 계수와 두 변수의 표준 편차의 곱과 같아야 한다는 것을 의미한다. 이는 두 변수 간의 선형 관계를 나타내는 중요한 수식이다 - 많은 금융 관계가 비선형적이기 때문에 상관관계가 이를 인식하지 못한다
- 이상치에 크게 영향을 받아 결과가 왜곡될 수 있다.
- 상관관계는 다변량 정규 분포를 벗어나면 의미가 없을 수 있다
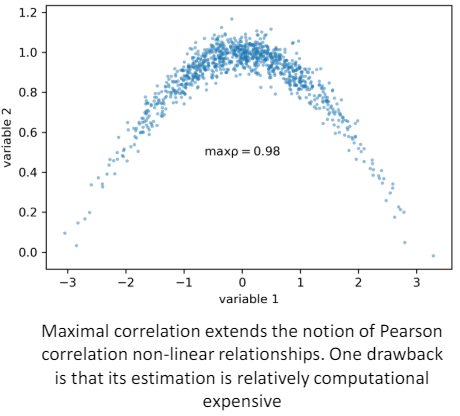
NON-LINEAR generalization of Pearson's Correlation
- Maximal Correlation
\[
\rho_{\text{max}}[X, Y] = \sup_{f:X \rightarrow \mathbb{R}, g:Y \rightarrow \mathbb{R}} \mathbb{E}[f(X)g(Y)]
\]- \( 0 \leq \rho_{\text{max}}[X, Y] \leq 1\) : 상관관계 값은 0에서 1 사이\(\rho_{\text{max}}[X, Y] = 0\) 이면 \(X\)와 \(Y\)는 독립이다
- \(\rho_{\text{max}}[X, Y] = 1\) 이면, \(f(X) = g(Y)\)를 만족하는 함수가 존재한다.
- \(X\)와 \(Y\)가 가우시안일때 \(\rho_{\text{max}}[X, Y] = |\rho[X, Y]|\)이다 즉 피어슨 상관관계의 절대값 동일하다
이 방법의 단점은 계산 비용이 상대적으로 높다는 것이다. 최대 상관을 찾기 위해 Alternating Conditional Expectations (ACE) 알고리즘을 사용할 수 있다
import numpy as np
from ace import model # https://pypi.org/project/ace/
def max_correlation(x: np.array, y: np.array) -> float:
# Get max correlation using ace package
# https://mlfinlab.readthedocs.io/en/latest/implementations/codependence.html
ace_model = model.Model()
ace_model.build_model_from_xy([x], y)
return np.corrcoef(ace_model.ace.x_transforms[0], ace_model.ace.y_transform)[0][1]
- Distance Correlation
\[
\rho_{\text{dist}}[X, Y] = \frac{dCov[X, Y]}{\sqrt{dCov[X, X] dCov[Y, Y]}}
\]
- \(dCov[X, Y]\) 는 \(X\)와 \(Y\)d의 doubly-centered Euclidean distance matrices의 average Hadamard product 다- \( 0 \leq \rho_{\text{dist}}[X, Y] \leq 1\) 상관관계 값은 0에서 1사이
- \(\rho_{\text{dist}}[X, Y] = 0\) 이면 \(X\)와 \(Y\)는 독립이다

import numpy as np, copy
from scipy.spatial.distance import pdist, squareform
def distcorr(Xval, Yval, pval=True, nruns=500):
# https://gist.github.com/wladston/c931b1495184fbb99bec
X, Y = np.atleast_1d(Xval), np.atleast_1d(Yval)
if np.prod(X.shape) == len(X): X = X[:, None]
if np.prod(Y.shape) == len(Y): Y = Y[:, None]
X, Y = np.atleast_2d(X), np.atleast_2d(Y)
n = X.shape[0]
if Y.shape[0] != X.shape[0]: raise ValueError('Number of samples must match')
a, b = squareform(pdist(X)), squareform(pdist(Y))
A = a - a.mean(axis=0)[None, :] - a.mean(axis=1)[:, None] + a.mean()
B = b - b.mean(axis=0)[None, :] - b.mean(axis=1)[:, None] + b.mean()
dcov2_xy = (A * B).sum() / float(n * n)
dcov2_xx = (A * A).sum() / float(n * n)
dcov2_yy = (B * B).sum() / float(n * n)
dcor = np.sqrt(dcov2_xy) / np.sqrt(np.sqrt(dcov2_xx) * np.sqrt(dcov2_yy))
if pval:
greater = 0
for i in range(nruns):
Y_r = copy.copy(Yval)
np.random.shuffle(Y_r)
if distcorr(Xval, Y_r, pval=False) > dcor:
greater += 1
return (dcor, greater / float(nruns))
else:
return dcor